
Research
Ph.D. Thesis: Automated Performance and Correctness Debugging for Big Data Analytics
My thesis can be found here. See below for additional details on publications or unlisted work.
Influence-Based Provenance for Dataflow Applications with Taint Propagation
Debugging big data analytics often requires a root cause analysis to pinpoint the precise culprit records in an input dataset responsible for incorrect or anomalous output. Existing debugging or data provenance approaches do not track fine-grained control and data flows in user-defined application code; thus, the returned culprit data is often too large for manual inspection and expensive post-mortem analysis is required.
Given a suspicious set of target output records, FlowDebug is designed to identify a highly precise set of input records based on two key insights. First, it precisely tracks control and data flow within user-defined functions to propagate taints at a fine-grained level by inserting custom data abstractions through automated source to source transformation. Second, it introduces a novel notion of influence-based provenance for many-to-one dependencies to prioritize which input records are more responsible than others by analyzing the semantics of a user-defined function used for aggregation. By design, our approach does not require any modification to the framework’s runtime and can be applied to existing applications easily. FlowDebug significantly improves the precision of debugging results by up to 99.9 percentage points and avoids repetitive re-runs required for post-mortem analysis by a factor of 33 while incurring an instrumentation overhead of 0.4X - 6.1X on vanilla Spark.
FlowDebug is published in the ACM Symposium on Cloud Computing 2020, which had a 24.4% acceptance rate. paper poster
PerfDebug: Performance Debugging of Computational Skew in Data-Intensive Scalable Computing
PerfDebug is a fine-grained performance provenance system that combines latency instrumentation with data provenance to investigate what we define as computational skew: skew in performance related not only to data skew (distribution), but also the computational latencies associated with individual records through program definition (e.g., user-defined functions). Although the current implementation uses Apache Spark, the underlying ideas and heuristics can be transferred to most other distributed cluster-computing frameworks. The project aims to provide application developers with the ability to answer computational skew queries such as "What are the latencies and input records associated with individual output records?" and "Which input records have the largest impact on job performance and why?".
PerfDebug is published in the ACM Symposium on Cloud Computing 2019, which had a 24.8% acceptance rate. paper poster
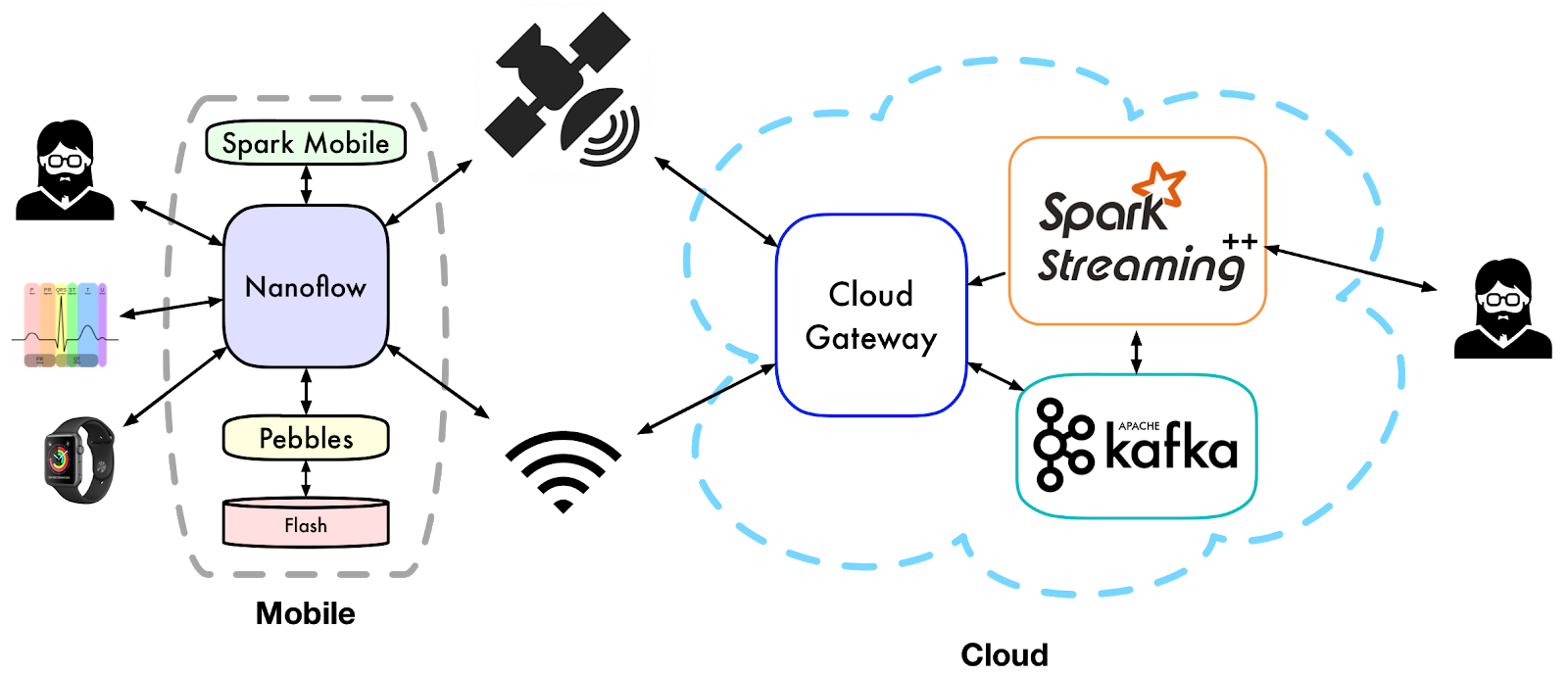
Nanoflow: Mobile Dataflow
Previously, I worked in the Scalable Analytics Institute (ScAi) under Professor Tyson Condie. There, I partnered with Joseph Noor to develop Nanoflow, a mobile dataflow processing framework integrated with cloud computing systems. In particular, we implemented a stream processing framework for Android devices that integrates with Apache Spark clusters. Using our system, application developers can submit a Spark job that operates on data originating from mobile data sources. Traditionally, such jobs require that all mobile data is pushed to the cluster, which then runs all required computations. Nanoflow instead integrates with Spark so that some computation (e.g., filters) can be automatically executed directly on the mobile device prior to data delivery to the computing cluster (Spark). By automatically splitting the execution graph and running some computation directly on mobile devices, our approach can improve job latency, throughput, and scalability while also tailoring jobs to account for mobile-specific requirements such as energy usage and network bandwidth limits.
Industry Experience
Please check my LinkedIn profile for industry experience.